
Cotton Bolls: April 2004 Archives
Document Actions
« March 2004 | トップページ | June 2004 »
2004.04.25
Compositeパターンによる入力チェック
目に見えない大きな流れ――
それを「世界」と言うのか「宇宙」と言うのかわかんないけど
オレもアルもその大きい流れの中のほんの小さなひとつ 全の中の一
だけどその一が集まって全が存在する
この世は想像もつかない大きな法則に従って流れている
その流れを知り分解して再構築する
それが錬金術
(荒川 弘:鋼の錬金術師6 より)
業務系のWebアプリでは,画面上にある数多くの項目に対して入力チェックを行う必要がある.例えば,次のような項目を考えてみよう:
期間: 年 月 日 〜 年 月 日
一見どこにでもありそうな開始日付と終了日付を入力するだけの項目だ.しかし,こんな単純なものでさえ入力チェックは複雑になる.少し考えただけでもチェック項目が次々と思い浮かぶだろう:
- 「月」は1から12までの数値が入る
- 「日」は1から31までの数値が入る
- 4月31日は不正
- うるう年でない年の2月29日は不正
- 「年」と「日」には値が入っているのに,「月」が空欄なのは不正
- 開始日付が終了日付より未来になっているのは不正
このように,数え上げたらきりがない.しかも実際の画面はもっと複雑で,上の期間入力は画面の片隅にある一項目にすぎない.一般には画面フォームに何十個も入力項目が並んでいるのが普通だ.それらすべてについて入力チェックを行わなければならない.
こういった複雑な処理を扱うときは抽象化が鍵となる.つまり,入力チェックとはどういうことなのかをつきつめて考えてみればよい.
例えば,上の期間入力は6つの項目で構成される.一つ一つは数値入力項目に過ぎないが,年,月,日3つの項目で一つの日付項目とみなすことができる.さらに開始日と終了日2つの日付項目を組み合わせると,全体として期間項目とみなすことができる.
これを画面全体まで広げよう.この期間入力は検索条件の一つに過ぎないかもしれない.例えば,顧客情報検索画面における契約日付のしぼり込み条件なのかもしれない.ということは,逆に画面全体は顧客情報検索項目という一つの入力項目とみなせる.すなわち「一は全,全は一」(鋼の錬金術師)だ.ここにCompositeパターンが適用できる余地がある:
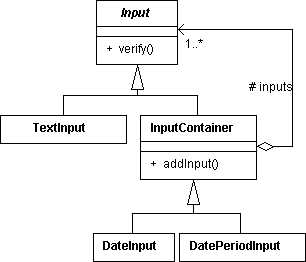
Inputが入力項目を表す抽象クラスだ.verifyメソッドを使って入力チェックを行う.TextInputがテキスト入力項目を表し,InputContainerがInputのCompositeクラスになっている.InputContainerの子クラスであるDateInputが日付項目だ.年,月,日3つのTextInputを持っている.また,DatePeriodInputが期間項目で,開始日と終了日2つのDateInputを持っている.
以上のことをJavaScriptで実装してみよう(ここからはJavaScriptによるオブジェクト指向プログラミングの知識が必要).目標は,入力チェックが
var FormInput = new InputContainer("顧客情報検索項目", ...);
FormInput.addInput(...);
...
FormInput.verify();
のように書けることだ.FormInputは画面全体の入力項目で,verifyメソッドを使って入力チェックする.もしエラーがあればエラーメッセージが表示され,エラー項目が選択されるとしよう.
まず入力エラーを表すクラスを定義する:
function InputError(message, input)
{
this.message = message;
this.input = input;
}
InputError.prototype.handleIt = function()
{
alert(this.message);
this.input.select();
}
InputErrorのコンストラクタにはエラーメッセージ(message)とエラー項目(input)を指定する.handleItメソッドでアラートを表示し,エラー項目を選択してユーザの再入力を促すことになる.
次にInputクラスを定義しよう:
function Input(subject, required)
{
this.subject = subject;
this.required = required;
}
Input.prototype.verify = function()
{
var err = this.searchError();
if (err != null) {
err.handleIt();
return false;
}
return true;
}
Inputクラスのコンストラクタには項目名(subject)と必須かどうか(required)を指定する.verifyメソッドでエラーを検索し,見つかればエラー処理を行いfalseを返すが,見つからなければtrueを返す.
次にInputクラスのエラー処理(searchError)の詳細を見てみる.一般に,入力エラーには次の2種類がある:
- 必須項目の未入力エラー
- 不正な値のエラー
このことから,searchErrorの中身を次のようにすればいい:
Input.prototype.searchError = function()
{
if (this.isBlank()) {
if (this.required)
return this.makeMissingError();
else
return null;
}
return this.searchValueError();
}
前半で未入力エラー,後半で不正な値のエラーを検索する.メソッド内のisBlankとsearchValueErrorは子クラスでオーバーライドすべきメソッドだ.makeMissingErrorメソッドは未入力エラーを生成するユーティリティメソッド.具体的には次のようになる(isBlank, searchValueError, selectメソッドは省略):
Input.prototype.makeMissingError = function()
{
return new InputError(this.subject + "を指定してください", this);
}
今度はInputContainerクラスを定義しよう.インスタンス変数inputsにInputオブジェクトを格納し,addInputメソッドでInputオブジェクトを追加する:
function InputContainer(subject, required)
{
this.temp = Input;
this.temp(subject, required);
this.inputs = new Array();
}
inherit(InputContainer, Input);
InputContainer.prototype.addInput = function(input)
{
this.inputs.push(input);
}
InputクラスからオーバーライドすべきisBlankメソッドとsearchValueErrorメソッドは次のようになる:
InputContainer.prototype.isBlank = function()
{
for (var i = 0; i < this.inputs.length; ++i) {
if (!this.inputs[i].isBlank())
return false;
}
return true;
}
InputContainer.prototype.searchValueError = function()
{
for (var i = 0; i < this.inputs.length; ++i) {
err = this.inputs[i].searchError();
if (err != null)
return err;
}
return this.searchTotalError();
}
最後出てきたsearchTotalErrorは全体として入力項目に矛盾がおきていないか調べるためのテンプレートメソッドだ.例えば,DateInputで4月31日のようなおかしい日付になっていないかのチェックはここで行う.
さて,テキスト入力項目を表すTextInputクラスを定義しよう.TextInputは,内部にTextboxオブジェクトを保持している.ここではコードの一部を紹介しよう:
function TextInput(subject, required, textbox)
{
this.temp = Input;
this.temp(subject, required);
this.textbox = textbox;
}
inherit(TextInput, Input);
TextInput.prototype.value = function() {
return this.textbox.value;
}
TextInput.prototype.setValue = function(arg) {
this.textbox.value = arg;
}
TextInput.prototype.select = function() {
this.textbox.select();
}
こいつの使い方は次の通りだ.例えば,「注文数」の数値入力項目があり,最大99個まで指定できるとする.HTMLが
注文数: <input id="QuantityText" size="2"> 個 <input id="OrderButton" type="button" value="注文">
のようになっているとき,TextInputを使ったJavaScriptのコードは次のようになる:
<script type="text/javascript">
var QuantityInput = new TextInput("注文数", true, document.all.QuantityText);
QuantityInput.numeric = true;
QuantityInput.min = 1;
QuantityInput.max = 99;
document.all.OrderButton.onclick = function() {
if (QuantityInput.verify())
alert(QuantityInput.value() + "個注文しました");
}
</script>
以上のようなことをDateInput, DatePeriodInputについて適用していけば,入力チェックの管理がだいぶ楽になる.
長くなりすぎたので具体的なコードはこの辺にしよう.詳しく知りたい人は,以下のファイルをダウンロードして解析してほしい.
さて,Inputクラスライブラリを作っていて予想外だったのが,未入力チェックの扱いがかなり自然にできることだ.例えば,InputContainer全体で任意項目でも,部品を必須項目として登録することでうまく設定できる.例えば次の「請求日」項目が任意項目だったとしよう:
var BillingDateInput = new DateInput("請求日", false,
document.all.BillingYearText,
document.all.BillingMonthText,
document.all.BillingDayText);
FormInput.addInput(BillingDateInput);
DateInputコンストラクタの第2引数がfalesなので任意項目ということになる.ところが,DateInputコンストラクタ内部では年,月,日を必須項目として登録している:
function DateInput(subject, required, yearText, monthText, dayText)
{
this.temp = InputContainer;
this.temp(subject, required);
this.yearInput = new TextInput(subject + "の年", true, yearText);
this.yearInput.numeric = true;
this.yearInput.min = 1900;
this.yearInput.max = 2100;
this.addInput(this.yearInput);
this.monthInput = new TextInput(subject + "の月", true, monthText);
this.monthInput.numeric = true;
this.monthInput.min = 1;
this.monthInput.max = 12;
this.addInput(this.monthInput);
this.dayInput = new TextInput(subject + "の日", true, dayText);
this.dayInput.numeric = true;
this.dayInput.min = 1;
this.dayInput.max = 31;
this.addInput(this.dayInput);
}
こうすると,年,月,日すべての項目が未入力の場合はエラーが発生しないが,月項目だけ入力すると年または日項目が未入力エラーと判断されるということだ.このように,Compositeパターンが未入力エラーの管理に対してもうまく働いている.
ところで,実際には上のようなJavaScriptだけでは不十分でサーバーサイドでも同じような入力チェックを行う必要がある.僕の場合,サーバー側でもパラレルにInputクラスライブラリ(もちろんJavaScriptではなくサーバーサイドの言語で)を作っているが,やはり2重管理になるのが嫌なところだ.この辺もいろいろ検討しているが,コードの自動生成ぐらいしか解答が見つかっていない.
01:03 PM | 固定リンク | コメント (10) | トラックバック
2004.04.11
DBのテスト
ここ数年RDBを使う仕事がほとんどなかったが,今回のシステムでSQL Serverを使うことになった.テストコードを書くために以前からOracleで使っていた方法があったのだが,SQL Serverでもちゃんと使えるようなのでひとまず安心した.
このテストのポイントは,2つのDBユーザを使い分けるということだ:
- 本番・受け入れテスト用ユーザ(マスターユーザ)
- 単体テスト用ユーザ(テストユーザ)
つまり,画面から実行するときはマスターユーザ,JUnitやNUnitから実行するときはテストユーザでデータベースにログインする.こうすることで,テーブルの内容を壊さないテストコードを書くことが可能だ.
具体的には次のようにすればいい.ここでマスターユーザをmaster,テストユーザをtest,単体テストで更新されうるテーブルをtableAとする:
- testユーザでデータベースにログイン
- master.tableAのコピーをtest.tableAとして新規作成
- テストを実行
- test.tableAを削除
この方法は,testユーザから見た場合tableA がmaster.tableAではなくtest.tableAになることを利用している.例えば実装コードの中に
insert into tableA ( field1, field2 ) values ( 1000, 'ABC' )
があったとしてもmaster.tableAではなくtest.tableAにインサートすることになる.だから,tableAをいくら更新しても master.tableAの内容はそのままだ.
テーブルのコピーを作成するSQL文はOracleとSQL Serverで異なる.Oracleの場合は
create table tableA as select * from master.tableA where 1 = 0
だが,SQL Serverの場合は次のようになる:
select into tableA from master.tableA where 1 = 0
ここでSQL文に where 1 = 0 があるのは空のテーブルでテストしたいからだ.そうする必要がない場合はwhere句がなくてもいい.
以上をふまえてTableSaverクラスを作る.これは,テストコードでテーブルを上書きされないようにするためのクラスだ:
public class TableSaver
{
private string userName;
private string masterName;
private SqlConnection con;
private IList tableNames = new ArrayList();
public TableSaver(string userName, string masterName, SqlConnection con)
{
this.userName = userName;
this.masterName = masterName;
this.con = con;
}
public void AddTable(string tableName)
{
string commandText
= String.Format("select * into {0}.{2} from {1}.{2} where 1 = 0",
userName, masterName, tableName);
SqlCommand cmd = new SqlCommand(commandText, con);
cmd.ExecuteNonQuery();
tableNames.Add(tableName);
}
public void Restore()
{
for (int i = tableNames.Count - 1; i >= 0; --i)
{
string tableName = (string) tableNames[i];
string commandText
= String.Format("drop table {0}.{1}", userName, tableName);
SqlCommand cmd = new SqlCommand(commandText, con);
cmd.ExecuteNonQuery();
}
}
}
TableSaverの使い方は次の通りだ.
TableSaver saver = new TableSaver("test", "master", con);
try
{
saver.AddTable("tableA");
saver.AddTable("tableB");
// テストの実行
...
}
finally
{
saver.Restore();
}
ここでTableSaverの作成はsetUpメソッド,TableSaver.Restore呼び出しはtearDownメソッドで行うことになるだろう.しかし,実際には個々のテストケースからTableSaverを直接呼び出すことはない.CommonTestCaseの方法を使うためだ.ここでは,DBテスト用CommonTestCaseとしてDbTestCaseを作る:
public class DbTestCase : CommonTestCase
{
protected SqlConnection con;
private const string CONNECTION_STR = "Data Source=...";
private TableSaver tableSaver;
private void CloseConnection()
{
con.Close();
}
private void RestoreTables()
{
tableSaver.Restore();
}
public override void SetUp()
{
base.SetUp();
converter = new SqlSelectConverter(converter);
con = new SqlConnection(CONNECTION_STR);
con.Open();
tableSaver = new TableSaver("test", "master", con);
TearDownHandlers += new TearDownHandler(RestoreTables);
TearDownHandlers += new TearDownHandler(CloseConnection);
}
protected void SaveTable(string tableName)
{
tableSaver.AddTable(tableName);
}
}
ここでTearDownHandlersはC#版TestSaverだと思ってもらえればいい.C#にはdelegateの仕組みがあるのでTestSaverインターフェイスをimplementsしたクラスを作る必要がない.
DbTestCaseを継承した個々のテストケースでは,SaveTableメソッドを呼び出してテーブルを保護する:
[Test]
public void Sample()
{
SaveTable("tableA");
SaveTable("tableB");
...
}
また,DbTestCaseにはSQL文を簡単に実行できるヘルパーメソッドも用意しておく:
protected void ExecuteSql(string commandText)
{
SqlCommand cmd = new SqlCommand(commandText, con);
cmd.ExecuteNonQuery();
}
このメソッドはSQL文を実行するメソッドだ.C#にはヒアドキュメントの機能があるため,このメソッドだけでもかなり使える.
[Test]
public void Sample()
{
ExecuteSql(@"
insert into tableA
(field1, field2) values
(1000, 'ABC');
insert into tableB
(field1, field2) values
(2000, 'XYZ');
");
...
}
長いSQL文が必要な場合はヒアドキュメントではなくファイルに書き込んで実行すればいい.これを実現するためのヘルパーメソッドは次の通り:
protected void ExecuteSqlFile(string fileName)
{
string resourceName = GetType().FullName + "." + fileName;
Assembly assembly = GetType().Assembly;
Stream input = assembly.GetManifestResourceStream(resourceName);
TextReader reader = new StreamReader(input);
try
{
ExecuteSql(reader.ReadToEnd());
}
finally
{
reader.Close();
}
}
例えばDbTestCaseを継承したテストケースをFooTestとし,FooTest/sample.sqlにSQLファイルを置けば次のようになる(注:sample.sqlはリソースとしてdllに埋め込むこと):
public class FooTest : DbTestCase
{
[Test]
public void Sample()
{
ExecuteSqlFile("sample.sql");
...
}
...
}
これだけあればDBのテストもかなり楽に書けると思う.前の記事で紹介したSqlSelectConverterもあるし.
なお,以上の方法はテーブル間にリレーションなど制約があれば使えないかもしれない.幸いそこまで複雑なRDBのシステムを扱ったことはないので,そういう仕事が来ればそのときに考えることになるだろう.
08:20 PM in XP | 固定リンク | コメント (0) | トラックバック
2004.04.04
NUnit Converter
今回の仕事はC#を使ったASP.NETのWebアプリ開発になった.これまでC#には全く興味がなかったので,モチベーションを上げるのに苦労した.言語が変わると何もかも不自由になってしまう.Visual StudioにQuick Fixとリファクタリング機能がないのは信じられないって感じだ.
まずはテストが書けないと話にならない.早速NUnitをインストールする.APIテストでC#の調査していると,NUnitが文字列比較で余計なことをしてくれることがわかった.JUnitのように同じ部分を省いてしまうのだ.しかもAssert.AreEquals引数にobjectのキャストを入れても回避できない.そこで,泣く泣くStringWrapperクラスを作る.これはNUnitにstringと解釈されないようにするためのラッパークラスだ:
public class StringWrapper
{
private string str;
public StringWrapper(string str)
{
this.str = str;
}
public override string ToString()
{
return str == null ? "(null)" : str;
}
public override bool Equals(object obj)
{
StringWrapper target = obj as StringWrapper;
if (target == null)
return false;
if (str == null)
return target.str == null;
return str.Equals (target.str);
}
public override int GetHashCode()
{
return str == null ? 0 : str.GetHashCode();
}
}
そしてdiffされると困るテストコードは次のように書く.
Assert.AreEqual(new StringWrapper(expected), new StringWrapper(actual));
ふう.
その後,ADO.NETでDataSetのテストコードを書くときに止まってしまう.DataSetはRDBのテーブル構造をそのまま表わしたようなクラスだ.なので,Converterなしのテストなんかやってられない.急いでJUnit ConverterをC#に移植する.NUnit Converterの作成だ.このとき,やっとC#のいいところが見つかった.すなわち,
- 可変長引数
- Boxing
の2つだ.
可変長引数は,BeanValueConverterとBeanConverterで役に立った.この2つのConverterはある特定のクラスのインスタンスをプロパティ値による文字列表現に変換する.可変長引数なら,プロパティを何個でも指定できる.JUnit Converterのように何個もコンストラクタを用意する必要がない:
Converter converter = new DefaultConverter();
converter = new BeanConverter(converter, typeof(Programmer),
"FirstName", "LastName", "Languages");
また,可変長引数は期待値の作成でも役に立った.以前このブログで書いた,すごく短い名前のファクトリーメソッドを使う方法だ:
object expected
= E.a(E.p("FirstName", "Masaru"),
E.ap("Languages", "Ruby", "Java", "EmacsLisp", "C#"),
E.p("LastName", "Ishii"));
converter.AssertEquals(expected, ishii);
ここでE.aは配列,E.pはProperty, E.apは配列の値を持つPropertyに変換するファクトリーメソッドだ(E:Expected, a:array, p:property, ap:array propertyの略).これでツリー構造の期待値の作成がかなり便利になった.
Boxingは,配列のConverterで役に立った.C#の場合,ICollectionへのConverer(CollectionConverter) ひとつでobject配列,int配列,ListArrayなどすべてに対応できる.JUnit Converterの場合,ObjectArrayConverter, IntArrayConverter, CollectionConverterと何種類も作らないといけなかった.Boxingの便利さが実感できる.
以上でConverterの機能は一通り実装できたが,他にもC#特有のIndexerConverterを作ってみた.これを使えばDataRowのテストコードの作成が楽になる.
[Test]
public void DataTable()
{
DataTable table = new DataTable("Songlines");
table.Columns.Add(new DataColumn("Track", typeof(int)));
table.Columns.Add(new DataColumn("Title", typeof(string)));
table.Columns.Add(new DataColumn("Artist", typeof(string)));
DataRow row;
row = table.NewRow();
row["Track"] = 1;
row["Title"] = "Roger The Miller";
row["Artist"] = "Karan Casey";
table.Rows.Add(row);
row = table.NewRow();
row["Track"] = 2;
row["Title"] = "She Is Like The Swallow";
row["Artist"] = "Karan Casey";
table.Rows.Add(row);
Converter converter = new DefaultConverter();
converter = new BeanValueConverter(converter, typeof(DataTable), "Rows");
converter = new IndexerConverter(converter, typeof(DataRow),
"Track", "Title", "Artist");
object expected
= E.a(E.a(E.p("Track", 1),
E.p("Title", "Roger The Miller"),
E.p("Artist", "Karan Casey")),
E.a(E.p("Track", 2),
E.p("Title", "She Is Like The Swallow"),
E.p("Artist", "Karan Casey")));
converter.AssertEquals(expected, table, 2);
}
このようにIndexerConverterにはインデックスキーを直接指定する.各キーの型からReflectionでIndexerを検索し,インデックス値を求めることになる.
後は,SQL Serverのテストで役に立つSqlSelectConverterも作ってみた.
[Test]
public void Songlines()
{
Converter converter = new DefaultConverter();
converter = new SqlSelectConverter(converter);
SqlSelect select
= new SqlSelect("SELECT track, title, artist" +
" FROM songlines " +
" ORDER BY track",
connection);
object expected
= E.a(E.a(1, "Roger The Miller", "Karan Casey"),
E.a(2, "She Is Like The Swallow", "Karan Casey"));
converter.AssertEquals(expected, select);
}
SqlSelectオブジェクトにSELECT文とSqlConnection,必要ならSqlTransactionを指定する.これでDB周りのテストがだいぶ楽になりそうだ.
NUnit ConverterのおかげでだいぶC#がわかってきた.後はNUnit Diff Addinか….こっちはかなり大変そうなので誰か作ってくれないかな.