|
|
|
|
 |
| JDK1.2 のコレクション概要 |
JDK1.2 の java.util パッケージには,新しいコレクション API が提供されて
いる.JDK1.1 までは Vector, Hashtable というコレクションが一般的に
使われていた.JDK1.2 でもこれらは引続きサポートされているが,新たに Collection(要素の集合),
List(インデクス付けされた要素列), Set(重複を許さない要素の集合),
Map(キーと値のペア) というインターフェイスが規定され,それらを実装する形で ArrayList,
LinkedList, HashSet, TreeSet, HashMap, TreeMap, WeakHashMap という
具体的なクラスが実現されている.
これまで馴染んできた Vector は新たにList インターフェイスを実装するように
なり,Hashtable は Map インターフェイスを実装するようにクラスの継承構造
が改められた.
Enumeration という要素の走査インターフェイスは,Vector や Hashtable
ではこれまで通りサポートされるが,新しいコレクションでは Iterator
という新しいインターフェイスが導入された.
また,Collections および Arrays というユーティリティクラスには,
ソートや検索などのアルゴリズムとクラス生成のファクトリメソッドがstatic
メソッドとして内蔵されている.
|
| まず使ってみる |
これまで,要素の集合を扱う時は Vector 等を利用してきたと思う.まずこれを新しい
List に置き換えてみる.Vector を使用したものと,List を使用したものを
並べて書いてみたので比較してみよう.
| JDK1.1 |
JDK1.2 |
// 生成
Vector v = new Vector();
// 要素の追加
v.addElement("1");
v.addElement("2");
v.addElement("3");
// 要素の走査と取得
Enumeration e = v.elements();
while (e.hasMoreElements())
System.out.println(e.nextElement());
// 要素の削除
v.removeElement("1");
// インデクスによる走査と取得
int n = v.size();
for (int i = 0; i < n; i++)
System.out.println(v.elementAt(i));
|
// 生成
List l = new ArrayList();
// 要素の追加
l.add("1");
l.add("2");
l.add("3");
// 要素の走査と取得
Iterator it = l.iterator();
while (it.hasNext())
System.out.println(it.next());
// 要素の削除
l.remove("1");
// インデクスによる走査と取得
int n = l.size();
for (int i = 0; i < n; i++)
System.out.println(l.get(i));
|
JDK1.2 の新しいコレクションAPI をJDK1.1 の古いコレクションAPIと 比べてみると,
以下の違いに気付く.
|
生成する型と変数の型が違う
JDK1.2 の List の生成は,
List l = new ArrayList();
という記述になっている.List はクラスではなくインターフェイスであり,
ArrayList が実際に生成されるオブジェクトのクラスである.JDK1.2 では List
インターフェイスを実装するクラスとして,ArrayList の他にも LinkedList など
が用意されている.ArrayList の代りに LinkedList を使用したい場合,この1行を,
List l = new LinkedList();
とするだけでよい.実際,Vector も List を実装するように変更されているため,
List l = new Vector();
も可能である.いくつかの実装から1つを選んでプログラミングすることができる.
|
メソッド名が簡潔
addElement() が add() に,elementAt() が get() に,
removeElement() が remove()に,それぞれメソッド名が対応する.
より簡潔な記述が可能となる.
|
Enumeration ではなく Iterator を使う
要素の走査に使用されていた Enumeration インターフェイスに代って,
Iterator インターフェイスが使用される.Iterator という名前は Enumeration
よりもより一般的な単語として普及しているし,Iterator のメソッド名も
hasMoreElement() が hasNext() に,nextElement() が next() にというように
簡潔な名前となっている.
新しいコレクションの雰囲気が分かったところで,コレクション API 全体の構成に目を向けよう.
|
| コアインターフェイス |
JDK1.2 コレクション API で提供されているクラスやインターフェイスは,
数は多いが設計は非常にすっきりとまとまっている.
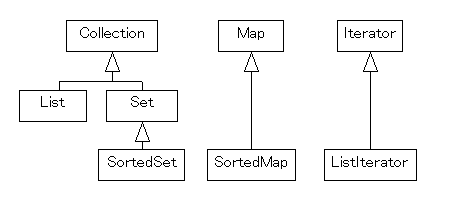
まず,基本となるのは次の4つのインターフェイスである.
- Colloction ...
要素の集まり.最上位のインターフェイス.
- List ...
要素が順序づけられ,インデクスでアクセスできる Collection.
- Set ...
要素の重複が許されない Collection.
- Map ...
キーと値のペア.これは Collection ではない.
これらの 4つに加えて,Set と Map にはそれぞれ1つずつサブインターフェイスがある.
- SortedSet ...
要素の順序が内部で維持されている Set.
- SortedMap ...
キーの順序が内部で維持されている Map.
これら6つをコレクション API のコアインターフェイスと呼ぶこと
がある.これらに加えて,Collection 中の要素を走査する Iterator がインターフェイスとして規定されている.
- Iterator ...
Collectin を走査するイテレータ.反復子や繰返子と訳されることがある.
- ListIterator ...
List のみから生成できる Iterator であり,逆戻りすることができる.
6つのコアインターフェイスと,2つのイテレータインターフェイスの継承関係は
図のようになる.
|
Collection インターフェイス
Collection は要素の集まりを表現するインターフェイスであり,最も基本となる
ものである.要素の登録,削除,数の問い合わせ,存在問い合わせ,
Iteratorの生成などのメソッドが基本となる.
| Collection インターフェイス |
| boolean |
add(Object o) |
指定した要素を追加する(optional) |
| boolean |
addAll(Collection c) |
指定した Collection の全要素を追加する(optional) |
| void |
clear() |
すべての要素を削除する(optional) |
| boolean |
contains(Object o) |
指定した要素が存在すれば true を返す |
| boolean |
containsAll(Collection c) |
この Collection に引数に指定した Collection の全要素が存在すれば true を返す |
| boolean |
isEmpty() |
この Collection が空であれば true を返す |
| Iterator |
iterator() |
この Collection 内の要素を走査するイテレータを返す |
| boolean |
remove(Object o) |
指定した要素が存在すれば,それを1つ削除する(optional) |
| boolean |
removeAll(Collection c) |
引数に指定した Collection 中の要素をすべてこの Collection から削除する(optional) |
| boolean |
retainAll(Collection c) |
引数に指定した Collection 中の要素だけを残して,他の要素をすべてこの Collection から削除する(optional) |
| int |
size() |
この Collection が含む要素数を返す |
| Object[ ] |
toArray() |
この Collection が含む要素の配列を返す |
| Object[ ] |
toArray(Object [ ]a) |
この Collection が含む要素を配列 a で指定された型の配列に返す.
十分なスペースがあればそれを上書きし,なければ new して戻り値とする |
表中 optional と書かれたメソッドは,必ずしもこれを実装するすべてのクラス
で実装されている訳ではない.特に,後で説明する「変更不能」Collection
を実装する場合,これらのメソッドは使用できず,
使用された場合にはUnsupportedOperationException が発生する.
|
List インターフェイス
List は Collection を継承して定義されてる.すなわち,Collection の持つメソッド
はすべて List にも適用可能である.List では,要素に順序が付けられインデクスで
アクセスが可能という特徴が付加されている.内部に次の要素への参照を持ついわゆる
「リスト構造」だけでなく,配列を用いて実装されたものも含む.
おなじみの Vector クラスは List インターフェイスの実装例であり,
実際 JDK1.2 では,Vector は implements List に改められている.
List では,Collection が持つメソッドに加えて,要素のインデクス
指定での挿入,置き換え,削除のようなメソッドのインターフェイスが規定されている.この後で説明する
Set と違って,通常は同じ要素を繰り返して追加することができる.すなわち,
2番目の要素と3番目の要素が同じということがありえる.
| List インターフェイス(Collectionとの差分) |
| void |
add(int index, Object element) |
指定した位置に要素を挿入する(optional) |
| boolean |
addAll(int index, Collection c) |
指定した Collection の全要素をリストの指定した位置に挿入する(optional) |
| Object |
get(int index) |
指定したインデクスの要素を返す |
| int |
indexOf(Object o) |
指定した要素のインデクスを返す.見つからなければ -1 |
| int |
lastIndexOf(Object o) |
指定した要素を末尾から探してインデクスを返す.見つからなければ -1 |
| ListIterator |
listIterator() |
この List を走査するListIterator を返す |
| ListIterator |
listIterator(int index) |
この List を指定インデクスから走査する ListIterator を返す |
| boolean |
remove(int index) |
指定したインデクスの要素を削除する(optional) |
| Object |
set(int index, Object o) |
指定したインデクスの要素を置き換える(optional) |
| List |
subList(int fromIndex, int toIndex) |
指定した fromIndex から toIndex の直前までの部分 List を返す |
|
Set インターフェイス
Set も Collection を継承して定義されている.これは数学の「集合」を
モデル化したもので,重複を許さない要素の集まりを表現する.
Set では,同じ値の要素を2回登録しても1つしか登録されないという特徴がある.
「同じ値」ということを正確に定義すると,2つの要素 e1 と e2 において
e1.equals(e2) == true という意味である.メソッドは Collection が規定
しているものと全く同じだが,要素の重複を許さないことから,例えば
add() メソッドにおいては「指定した要素が既に存在していなければ追加する」という意味になる.
SortedSet インターフェイス
SortedSet は Set を継承して定義されている.特に,要素の順序が Set 内で維持されて
いるという特徴を持つ.
| SortedSet インターフェイス(Set との差分) |
| Comparator |
comparator() |
この SortedSet に使用されている Comparator を返す(Comparable による自然な大小関係を使用している場合は null) |
| Object |
first() |
最初の要素を返す |
| SortedSet |
headSet(Object toElement) |
引数で指定された要素よりも小さい要素からなる SortedSet(サブセット)を返す |
| Object |
last() |
最後の要素を返す |
| SortedSet |
subSet(Object fromElement, Object toElement) |
引数に指定された fromElement 以上で toElement より小さい要素からなる
SortedSet(サブセット)を返す.
|
| SortedSet |
tailSet(Object fromElement) |
引数で指定された要素以上の要素からなる SortedSet(サブセット)を返す |
この SortedSet から生成された Iterator は,昇順に要素を
走査することができる.「昇順」を定義するためには要素の大小関係が規定されていなければ
ならないが,この大小関係は java.lang.Comparable インターフェイス,および
java.util.Comparator インターフェイスによって規定される.
JDK1.2 から,String や Character および Integer, Long, Double などの数値を表現
する java.lang のクラス群が Comparable インターフェイスを実装するようになり,
これらのクラスのオブジェクトについては「自然な大小関係」が規定されるようになった.
また,自前でこの大小関係を規定したい場合は, SortedSet を生成する際にユーザ定義の
Comparator クラスのオブジェクトを指定することが可能である.
自作のクラスを SortedSet に格納するには,そのクラスを Comparable を実装するように
するか,もしくはその自作クラスを引数に受け取れる Comparator を定義する.
| Comparable インターフェイス(java.lang パッケージ) |
| int |
compareTo(Object o) |
この オブジェクトと引数で与えられたオブジェクトの大小関係を返す.
(0 は等しい,負の値は this が o より小さい, 正の値は this が o より多きい) |
| Comparator インターフェイス |
| int |
compare(Object o1, Object o2) |
o1 と o2 の大小関係を返す.(0 は等しい,
負の値は o1 が o2 より小さい, 正の値は o1 が o2 より大きい) |
| boolean |
equals(Object obj) |
Comparator 同士の一致検査 |
Map インターフェイス
Map は「キー」と「値」のペアを保持するインターフェイスである.
このペアを登録しておけば,後でキーを指定することによって値を素速く
取り出すことができる.キーと値のペアをエントリ(Entry)と呼ぶ.
おなじみの Hashtable クラスは Map インターフェイスの実装例であり,
JDK1.2 では Hashtable は implements Map に改められている.
Map では,キーと値のペアを指定しての登録,キーを指定して
値の取り出し,キーを指定してエントリの削除,などの基本メソッドが規定されている.
| Map インターフィス |
| インナークラス |
Map.Entry |
キーと値のペア |
| void |
clear() |
すべてのエントリを削除する |
| boolean |
containsKey(Object key) |
指定したキーが存在すれば true を返す |
| boolean |
containsValue(Object value) |
指定した値が1つ以上存在すれば true を返す |
| Set |
entrySet() |
この Map の全エントリを Set として返す(エントリの Set ビュー) |
| Object |
get(Object key) |
指定したキーの値を返す |
| boolean |
isEmpty() |
この Map が空であれば true を返す |
| Set |
keySet() |
この Map の全キーを Set として返す(キーの Set ビュー) |
| Object |
put(Object key, Object value) |
キーと値のペアをエントリとして追加する(optional) |
| void |
putAll(Map t) |
指定した Map のキーと値のペアをすべて追加する(optional) |
| Object |
remove(Object key) |
指定したキーが存在すればそれを削除する(optional) |
| int |
size() |
この Map が含むエントリ数を返す |
| Collection |
values() |
この Map のすべての値を Collection として返す(値の Collection ビュー) |
Map は Collection を継承していないが,Map を Collectin 的に操作した
い場合が多々ある.この様な場合,Map から「Collection ビュー」を取り出す
ことができる.Map から生成された Collection ビューに対して
Collection のメソッドを適用することで,生成元の Map を操作する
ことが可能である.Collection ビューを取り出すために,次の3つの
メソッドが使用できる.
- entrySet() ... エントリを Set として扱うビュー
- keySet() ... キーを Set として扱うビュー
- values() ...値を Collection として扱うビュー
次の例で,Map に適当なキーと値のペアを設定し,それを Collection ビューを
使って Collection 的に扱う例を挙げる.
// キーと値の準備
String[] key = { "Apple", "Melon", "Banana" };
String[] value = { "Red", "Green", "Yellow" };
// Map の生成
Map m = new HashMap();
// Map にキーと値をセット
for (int i = 0; i < key.length; i++)
m.put(key[i], value[i]);
// Map の Collection ビューを取り出し,Iterator を作成
Iterator it = m.entrySet().iterator();
// すべてのエントリを出力
while (it.hasNext()) {
Map.Entry e = (Map.Entry)it.next();
System.out.println("Key: " + e.getKey() + ", Value: " + e.getValue());
}
|
SortedMap インターフェイス
SortedMap は Map を継承して定義されている.特に,要素の順序が Map 内で維持されて
いるという特徴を持つ.これは SortedSet と Set の関係と同じである.SortedSet
同様,キーに対する Comparable または Comparator によって要素間の大小関係が規定される.
| SortedMap インターフェイス(Map との差分) |
| Comparator |
comparator() |
この SortedMap に使用されている Comparator を返す(Comparable による自然な大小関係を使用している場合は null) |
| Object |
firstKey() |
最初のキーを返す |
| SortedMap |
headMap(Object toKey) |
引数で指定されたキーよりも小さいキーを持つ要素からなる SortedMap(サブセット)を返す |
| Object |
lastKey() |
最後のキーを返す |
| SortedMap |
subMap(Object fromKey, Object toKey) |
引数に指定された fromKey 以上で toKey より小さいキーをもつ要素からなる
SortedMap(サブセット)を返す.
|
| SortedMap |
tailMap(Object fromKey) |
引数で指定されたキー以上のキーをもつ要素からなる SortedMap(サブセット)を返す |
Iterator インターフェイス
Vector や Hashtable に対する Enumeration 同様,Collection
では Iterator を取り出して1つ1つの要素を走査する.
任意の Collection から iterator() メソッドで Iterator オブジェクトを取得
することができる.また,Enumeration にはなかった remove() という要素を
削除するメソッドも追加されている.
| Iterator インターフェイス |
| boolean |
hasNext() |
次の要素が存在すれば true を返す |
| Object |
next() |
次の要素を取り出す |
| void |
remove() |
最後に取り出した要素を Collection から削除する(optional) |
ListIterator インターフェイス
List では,Iterator よりきめ細かい走査ができる ListIterator を生成することができる.
ListIterator は,順方向に進むことができるのはもちろん,逆方向に戻るメソッドや
List を修正するメソッドも定義されている.
| ListIterator インターフェイス(Iterator との差分) |
| void |
add(Object o) |
指定された要素を List に追加する(optional) |
| boolean |
hasPrevious() |
逆方向に次の要素が存在すれば true |
| int |
nextIndex() |
次の要素のインデクスを返す |
| Object |
previous() |
逆方向に次の要素を取り出す |
| int |
previousIndex() |
逆方向に次の要素のインデクスを返す |
| void |
set(Object o) |
指定された要素を List の最後に取り出された要素と置き換える(optional) |
|
| コアインターフェイスを実装するクラス |
さて,コレクション API の基本となる Collection, List, Set, Map
インターフェイスについて理解したところで,それらのインターフェイスを実装している実際のクラス群を見ていく.
- List ... ArrayList, LinkedList, Vector, Stack
- Set ... TreeSet, HashSet
- Map ... HashMap, TreeMap, Hashtable
コアインターフェイスを使用するには具体的なオブジェクトを new
する必要があるが,当然のことながらインターフェイスは直接 new
できないため,上記の実装クラスの中から実際に使用する実装を選ぶことに
なる.ユーザが実装クラスを選べる点が,コレクション API を利用する際の大きな利点である.
各実装には実行時の速度やメモリ容量の効率に関する長所短所があり,
これらを踏まえて実装クラスを選ぶ.
|
List を実装するクラス
List を実装するクラスとしては,ArrayList と LinkedList が用意されている.
また,以前から存在している Vector およびそのサブクラスである Stack も
List を実装したものとなっているが,ここでは省略した.
・ArrayList
配列を実装に使った List .Vector とほぼ同じと考えてよい.
ArrayList は List や Collection のデフォルトの実装として使用でき,
汎用のオブジェクトコンテナとして最も妥当なものである.
これまで Vector を使用してきた場面では,ほとんどの場合 ArrayListが適当である.
- 長所: 要素へのランダムアクセス(インデクス指定の get, setの呼び出し)が高速.
LinkedList に比べて,メモリ容量がコンパクトですむ.
- 短所: 要素列の中間への挿入,削除に時間がかかる.
実装に配列を使用していることから,これらの長所短所は容易に想像がつくだろう.
・LinkedList
双方向リストを実装に使った List.
- 長所: 要素列の中間への挿入,削除が高速.シーケンシャルなアクセスには最適.
- 短所: インデクス指定のランダムアクセスには時間がかかる.ArrayList に比べてメモリ容量を多少多く必要とする.
この性質もプログラマには分かりやすい.
|
Set を実装するクラス
Set を実装するクラスとしては,HashSet と TreeSet が用意されている.
・HashSet
ハッシュを使った Set の実装.Set のデフォルトの実装として
適当なものである.追加された要素は,要素の持つ hashCode メソッドを使用して
ハッシュ値に対応したバケット(同じハッシュ値を返すものの列)へと
振り分けられて管理される.
- 長所: 要素数によらない高速な検索が可能.
- 短所: 要素はよい hashCode メソッドを実装する必要がある.
要素の登録順などによって Iterator が返す要素の順序が変わる.
・TreeSet
赤黒木(Red-Black Tree)を使った実装である.これは2分木の一種であり,要素数nに対してlog(n)オーダーの時間
で検索が可能.内部で常に要素の順序を維持しており,SortedSet を実装している.
- 長所: 要素は常に一定の順序を保っている(SortedSet).
- 短所: 要素は Comparable を実装するか,別に Comparator を用意する必要がある.
|
Map を実装するクラス
Map を実装するクラスとしては,HashMap と TreeMap が用意されている.
これらの特徴は,対応する Set と同じである.Hashtable も使用できるがここでは省略した.
・HashMap
ハッシュを使った Map の実装.Map のデフォルトの実装として適当なものである.
- 長所: 要素数によらない高速な検索が可能.
- 短所: 要素はよい hashCode メソッドを実装する必要がある.
・TreeMap
赤黒木(Red-Black Tree)を使った実装.TreeSet 同様
要素数nに対してlog(n)オーダーの時間で検索が可能である.内部では常に順序が維持され,SortedMap を実装している.
- 長所: 要素は常に一定の順序を保っている(SortedMap).
- 短所: 要素は Comparable を実装するか,別に Comparator を用意する必要がある.
6つのコアインターフェイスとそれぞれの実装クラスの関係を図にすると次のようになる.
|
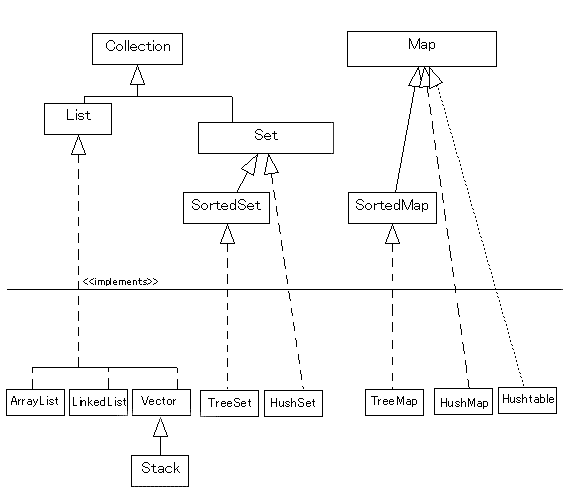
ここまでで,基本的なコアインターフェイスとその実装クラス
が理解できたと思う.次に,Collections および Arrays という
ユーティリティクラスで提供されている機能の説明に移ろう.
|
| ユーティリティクラス Collections, Arrays |
Collections と Arrays (これらのクラス名の最後に s が付いている
ことに注意)は,ユーティリティクラスと呼ばれ,便利な static 定数,static メソッドが定義されている.
同期化(synchronized) Collection
コレクションの実装クラスのメソッドは,どれ1つとして synchronized
とはなっていない.よって,このままではマルチスレッドに適用することが
できない.同期化に関して,コレクション API では
「外部同期化(external synchronization)」と呼ばれる設計を採用している.
この手法では,Collections ユーティリティクラスの static メソッドである
synchronizedCollection() を使用することによって,任意の Collection から
同期化された Colleciton を取り出すことができるようになっている.
これによって,必要に応じた同期化が可能となる.
Collection c = new ArrayList();
c.add("1");
//.....
Collection syncCollection = Collections.synchronizedCollection(c);
// syncCollection は同期化されている.
//...
|
synchronizedCollection() の他にも,synchronizedMap(), synchronizedSet() 等が
用意されている.
|
変更不能(unmodifiable) Collection
同様に,Colleciton を変更不能にすることも可能である.
Collections ユーティリティクラスの static メソッドである
unmodifiableCollection() を使用する.こうして得られた
Collection に対して変更を伴うメソッドを適用した場合には,
UnsupportedOperationException が発生する.ここで変更を伴うメソッド
とは,コアインターフェイスの説明の表中 optional と書かれたメソッドである.
Collection c = new ArrayList();
c.add("1");
Collection constCollection = Collections.unmodifiableCollection(c);
// constCollection は変更不能
try {
constCollection.add("2"); // 変更メソッド
} catch (UnsupportedOperationException e) {
// ここに来るはず
System.out.println("Unmodifiable Collection !");
}
|
unmodifiableCollection() の他にも,unmodifiableMap(), unmodifiableSet() 等が
用意されている.
|
無名(anonymous)の Collection 実装
Collection インターフェイスを実装するいくつかの無名の実装が
ある.ここで無名というのは,anonymous クラスのことであり,
インナークラス構文を使ってクラス名がないオブジェクトとして作成されるものである.
これらは,Collections および Arrays ユーティリティクラスの
static メソッドおよび static 属性で用意されている.
- Collections.EMPTY_SET ... 空の Set を表現する Set 型の定数
- Collections.EMPTY_LIST ... 空の List を表現する List 型の定数
- Collections.EMPTY_MAP ... 空の Map を表現する Map 型の定数(since JDK1.3)
- Collections.singleton(Object o) ... 1つの要素のみを含む Set を作るファクトリメソッド
- Collections.singletonList(Object o) ... 1つの要素のみを含む List を作るファクトリメソッド(since JDK1.3)
- Collections.singletonMap(Object key, Object value) ... 1つの要素のみを含む Map を作るファクトリメソッド(since JDK1.3)
- Collections.nCopys(Object o) ... 同じオブジェクトを n 個含む List を作るファクトリメソッド
- Arrays.asList(Object []a) ... 配列の List ビューを取り出すファクトリメソッド
アルゴリズム
C++ の STL(Standard Template Library)のように,いくつかのアルゴリズムが用意されている.
- Collections.sort(List l) ... クイックソート
- Collections.binarySearch(List l, Object key) ... バイナリサーチ
- Collections.min(Collection c) ... 最小値検索
- Collections.max(Collection c) ... 最大値検索
- Collections.fill(List l, Object val) ... 同じ要素の詰め込み
- Collections.copy(List dest, List src) ... コピー
- Collections.reverse(List l) ... 要素の順序反転
- Collections.shuffle(List l) ... 要素のランダムな並び替え
- Collections.rotate(List l, int distance) ... 要素の回転(since JDK1.4)
- Collections.replaceAll(List l, Object oldValue, Object newValue) ... 要素の置換(since JDK1.4)
- Collections.indexOfSubList(List source, List target) ... サブリストの位置(since JDK1.4)
- Collections.lastIndexOfSubList(List source, List target) ... サブリストの位置(since JDK1.4)
- Collections.swap(List l, int i, int j) ... 要素の交換(since JDK1.4)
- Collections.list(Enumeration e) ... Enumeration から List の生成(since JDK1.4)
- Arrays.sort(Object[] a) ... 配列のクイックソート
- Arrays.binarySearch(Object[] a, Object key) ...配列のバイナリサーチ
- Arrays.equals(Object[] a1, Object[] a2) ...配列の一致検査
- Arrays.fill(Object[] a, Object val) ... 配列への同じ要素の詰め込み
上記中 Arrays は Object の配列に対するメソッドのみ記述したが,
他にも int , long 等の基本型の配列に対するアルゴリズムも用意されている.
|
| 各クラスの生成,変換関係 |
ここで,これまでに紹介したコアインターフェイス同士の生成,変換関係を図にしてみると,次のようになる.
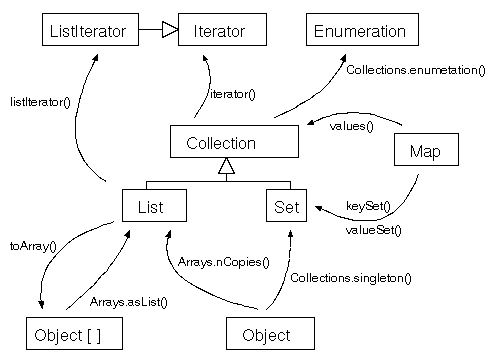
これで,コレクション API の全貌がほぼ明らかになった.
次に,コレクション API を利用する際のいくつかのヒント,イディオムを紹介しよう.
|
| 使い方のヒント |
コレクション API になれたところで,ちょっとした気の効いたイディオム(常套句)
を集めてみた.これらを知っていると,やりたいこと簡潔にを表現できる.
java.awt.List との名前の衝突回避
java.util.List と java.awt.List は同じクラス名である.java.awt パッケージと
java.util パッケージの両方を使用するクラスでは,名前が衝突してしまう.
これは,以下のような import 文で回避することができる.
import java.util.*;
import java.awt.*;
import java.util.List;
// ... 以下,List は java.util.List を指す
|
同一値の要素をすべて削除
Collection の remove() メソッドは,最初に見つかった要素のみを
削除する.Set など,同じ値を持つ要素が1つしかない場合はそれで
よいが,List 内のすべての同一値を一度に削除するには次のようなイディオムを使う.
// "1" という値を持つ要素をすべて削除
void removeAllOne(List l) {
l.removeAll(Collections.singleton("1"));
}
|
この例では,Collections ユーティリティクラスの singleton() ファクトリ
メソッドをうまく使って,Collection の removeAll() と
組み合わせている.
指定型の配列に要素を取り出したい
Collection に入っている要素の型が分かっていて,それらを配列として取り出したい場合,
引数なしの toArray() メソッドを呼ぶと戻り値が Object[] となり扱いにくいことがある.
これに対して,toArray(Object[] a) を使用すると戻り値を引数 a で指定した型の配列に変換してくれる.
// String の Collection を作る
Collection strings = new ArrayList();
strings.add("1");
strings.add("2");
// 引数なしの toArray() では ClassCastException が発生
String[] s = (String [])strings.toArray(); // 例外!
// これなら大丈夫
String[] s = (String [])strings.toArray(new String[0]);
System.out.println(s[0]);
|
toArray(Object[] a) は,引数に指定した配列の容量があればそれを
上書きする仕様だが,上記のようにサイズ 0 の配列を指定するイディオムを覚えておくとよい.
どうしても Enumeration を使いたい
Collection からは通常 Iterator を生成するが,どうしても Enumerationが使いたければ,次のようにする.
class HalfOldClass {
Collection c = new ArrayList();
// ....
Iterator getIterator() {
return c.iterator();
}
Enumeration getEnumeration() {
return Collections.enumeration(c);
}
}
|
JDK1.4 からは,逆に Enumeration から Collection(List) を生成するユーティリティメソッドも用意された.
class LegacyBridgeClass {
OldClass c;
// ....
List getList() {
return Collections.list(c.enumeration());
}
}
|
配列とコア・インターフェイスの変換
要素の集合を扱うのに,配列を利用するケースも多いだろう.
String[] s = new String[30];
配列とコア・インターフェイスの橋渡しをする便利なメソッドがある.配列を
Collectionとして扱うには,Arrays.asList() を使う.
List l = Arrays.asList(s);
List l に対する読みだしはもちろん,書き込みも Collection として行え,変更は
元の配列にライト・スルーされる.
逆に,配列を取り出すには,前のイディオムである,Collection.toArray() メソッドを使用する.
new するオブジェクトの型と変数の型を分ける
コーディングを行う上の注意点として,new したクラスの参照を保持する
変数の型としてコアインターフェイスを使用することを推奨する.冒頭でも
述べたとおり,new には具体的な実装クラスを与え,
それを受ける変数の型にはインターフェイス型を使用する.
List list = new ArrayList();
また,自分が作成するメソッドの引数やクラスのインスタンス変数の
型も,コアインターフェイスにしておく.従って,実装クラスのクラス名
が現れるのは new の直後だけ,ということになる.こうしておけば,
将来期待する速度が得られなかった場合などに new の1行だけを書換えること
によって,あとのコードは変更しなくても実装クラスを交換することが可能に
なる.実装クラスには生の配列だって使うことができる(ただし固定サイズ)!
List list = new Arrays.asList(new Object [30]);
|
| 最後に |
JDK1.2 のコレクションAPIを一通り解説した.この API のパワーとスマートさを理解できたと思う.
特に,あなたがもし新たに再利用可能なパッケージを作成することを考えている場合,
そのインターフェイスにはこの API を積極的に利用すべきだ.新しいコレクション API に
統一することで,別に開発された他のパッケージのインターフェイスとの協調が
楽になり,パッケージを組み合わせて使用するユーザに取って大きなメリットを与えることができる.
最後に,簡単な演習問題を用意した.解答例は,こちら。
|
| 演習問題 |
- String を要素に持つ Collection オブジェクト c がある.要素のうち,null, "" を値として持つものを無効として除外せよ.
Collection c = new ArrayList();
c.add("1");
c.add(null);
c.add("2");
c.add("");
c.add("3");
┌───────────┐
│答え │
└───────────┘
System.out.println(c); //[1, 2, 3] という出力
- 2つの Set s1, s2 がある.これらの和集合(or),差集合(diff),積集合(and)をそれぞれ求めよ.
Set s1 = new HashSet(Arrays.asList(new String[] {"1", "2", "3"}));
Set s2 = new HashSet(Arrays.asList(new String[] {"0", "2", "4"}));
Set or, diff, and;
// 和集合(or = s1 + s2)
┌───────────┐
│答え │
└───────────┘
System.out.println(or);
// [0, 1, 2, 3, 4] という出力(順序は問わない)
// 差集合(diff = s1 - s2)
┌───────────┐
│答え │
└───────────┘
System.out.println(diff);
// [1, 3] という出力(順序は問わない)
// 積集合(and = s1 * s2)
┌───────────┐
│答え │
└───────────┘
System.out.println(and);
// [2] という出力
- 単語の配列 String [] words がある.この配列に重複して現れる単語を除去した
配列,String[] uniq を生成せよ.
String[] words = { "1", "2", "1", "4", "3", "2" };
String[] uniq;
┌───────────┐
│答え │
└───────────┘
for (int i = 0; i < uniq.length; i++)
System.out.println(uniq[i]);
// 1, 2, 3, 4 という出力
- 英単語(String)の配列をアスキー順にソートせよ,次に逆順にソートせよ.
最後に大文字小文字の区別なく辞書順にソートせよ.
String[] words = { "c", "E", "A", "B", "d" };
┌───────────┐
│答え │
└───────────┘
for (int i = 0; i < words.length; i++)
System.out.println(words[i]);
// A, B, E, c, d という出力
┌───────────┐
│答え │
└───────────┘
for (int i = 0; i < words.length; i++)
System.out.println(words[i]);
// d, c, E, B, A という出力
┌───────────┐
│答え │
└───────────┘
for (int i = 0; i < words.length; i++)
System.out.println(words[i]);
// A, B, c, d, E という出力
- 0~9の文字のみからなる文字列を,整数とみなして昇順に並べて保持する
SortedSet s を生成せよ.
SortedSet s;
┌───────────┐
│答え │
└───────────┘
s.add("123458");
s.add("123");
s.add("34");
System.out.println(s);
// [34, 123, 12345] という出力
- Map m からキーのみ,値のみをそれぞれ配列として取り出せ.
Map m = new HashMap();
m.put("apple", "red");
m.put("melon", "green");
m.put("banana", "yellow");
String[] keys;
String[] values;
┌───────────┐
│答え │
└───────────┘
for (int i = 0; i < keys.length; i++)
System.out.println(keys[i]);
// melon, apple, banana という出力
for (int i = 0; i < values.length; i++)
System.out.println(values[i]);
// green, red, yellow という出力
|
| 参考 URL |
質問,感想は,平鍋まで.
Copyright (C) Kenji Hiranabe 1998, 1999
|
この記事への評価にご協力をお願いします。
|
|
